
近日大火的聊天機器人程序ChatGPT,最終還是崩了!多位用戶反映,其網站因為運算量過大,出現了無法回復的情況。
翻譯:我們出現了遠超預想的(運算)需求,請再堅持一下并等待我們將系統擴展。
事實上,ChatGPT出現崩潰只是算力緊張的一個縮影。近日隨著百度、京東、騰訊等國內廠商宣布參與智能聊天機器人領域的競爭,未來類似ChatGPT這樣的程序將越來越多。人工智能發展是大勢所趨,全球市場對于算力的需求也將出現快速的增長。
GPU的“變種”在算力領域“擠走”CPU
提到算力,首先不得不說的就是CPU(Central Processing Unit,中央處理器)。1971年,英特爾生產的4004微處理器將運算器和控制器集成在一個芯片上,標志著CPU的誕生,這也是大規模機器運算的開始。后來從四位運算開始,每隔幾年處理器的性能就會翻倍。
再之后,單純的運算位數增加已不再滿足復雜的運算需求,CPU逐漸向更多核心,更高并行度發展。典型的代表有英特爾的酷睿系列處理器和AMD的銳龍系列處理器。
CPU最大的特點是全能,作為中央處理器,其性能被平均分為多個模塊,也因此CPU可以完成絕大多數指令下的任務,整體屬于一款較為均衡的產品。
與此同時,由于電腦顯示器的出現,傳統的GPU(Graphics Processing Unit,圖形處理器)也應運而生。顯示器上的圖形顯示需要大量的重復運算(顯示各種顏色,甚至三維圖像),其對于算力的要求要遠高于以處理指令為主的CPU。因此不同于CPU,GPU更強調了并行計算的方法,這也讓GPU無論是算力還是運算速度,都要高于CPU。
隨著顯示器分辨率的不斷提升,特別是多款大型游戲對于顯示器分辨率的要求越來越高,GPU的運算性能也在飛速提升,而且提升速度快于CPU。
在這一方面,英偉達占據了GPU市場的頭把交椅,不少人應該都有過為了某款熱門游戲,而單獨安裝英偉達顯卡的經歷。
很長一段時間以來,CPU負責中央控制和各種運算,GPU負責少量處理和大量重復運算,兩者相輔相成,各自擔負起了對應的職能。
然而,有人看到了GPU相對于CPU高算力的優勢,于是一種去掉了GPU圖形處理部分內容,而僅保留了科學計算,AI訓練、推理任務等通用計算類型的GPGPU(General-Purpose computing on Graphics Processing Units,通用圖形處理器)誕生了。
GPGPU,可以說是特化版的運算芯片,GPGPU通過 GPU 多條流水線的并行計算來實現大量計算。超長流水線的設計以吞吐量的最大化為目標,在對大規模的數據流并行處理方面具有明顯的優勢。
如果說普通CPU的計算能力是小溪流,那么GPGPU的計算能力就是并行了注入多條河流的大江長河。在未來人工智能爆發的時代,其遠優于CPU的運算性能,決定了這個GPU家族的“變種”在算力領域將“擠走”傳統的CPU,大規模應用于算力市場中。
事實上,此前就有消息表示,ChatGPT已導入了至少1萬個英偉達高端的GPGPU,不論此消息是否屬實,ChatGPT至少很大概率使用了大量的GPGPU,并且好像已投入的部分還不夠用,需要更多。一個高端GPGPU動輒數十上百萬,這樣看來,GPGPU的市場空間可能會非常大。
GPGPU生態:英偉達業內領先,國內生態初見雛形
事實上,一般的GPGPU確實具備了超快速的運算能力,然而,要想達到ChatGPT這種真正具備一定解決問題能力的成型AI系統,仍需要大量的開發工作,特別是需要海量的深度學習支持。AI才能面對并有效處理海量的問題。深度學習與GPU的圖形處理有一些相通的地方,它需要大量的數據來“訓練”模型。比如一個貓圖識別AI,需要提供數以萬計的貓圖供其“學習”。而每一張貓圖的學習又與其他貓圖沒有先后關系,每一張貓圖,其實就相當于一次學習。
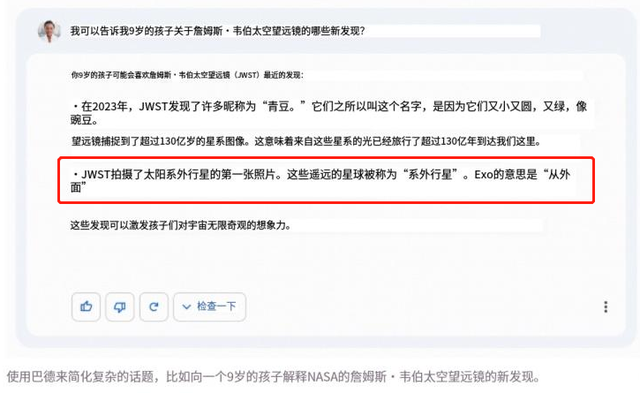
?而如果缺少這些必要的開發學習支持,否則的話,GPGPU空有大量的運算能力,卻不一定能夠做出正確的運算。例如,前兩天谷歌Bard的發布會中,就犯了事實性的錯誤,在一個“關于詹姆斯·韋伯太空望遠鏡(JWST),我可以告訴我9歲的孩子它有哪些新發現?”的問題中,Bard給出的一個答案是:太陽系外行星的第一張照片,是用JWST拍攝的。然而事實上,2004年,第一張系外行星照片是由歐洲南方天文臺的甚大望遠鏡(VLT)拍攝的。
這種學習、運算與開發的過程,往往需要一個統一的開發架構,架構越優秀、越適配GPGPU。開發的效果也會越好。在這一領域,英偉達的優勢比較明顯,英偉達的CUDA(Compute Unified Device Architecture,統一計算架構)集成技術,占據了全球八成以上的GPGPU開發市場。通過這個技術,用戶可利用英偉達的GPU進行圖像處理之外的運算。由于絕大多數架構都是針對CPU進行編程的,更突顯出了英偉達該架構的稀缺性。
不過,最近英偉達也遇到了越來越多的挑戰,首先是一款新的架構PyTorch在AI開發領域大有后來居上的架勢,由于其將支持更多GPU,相比于英偉達對GPU領域的壟斷,受到了很多廠家的歡迎。而后續OpenAI(推出ChatGPT的公司)又發布了一款開源的GPU開發架構Triton。其雖然可以看作簡化版的CUDA,但由于其采用較易編碼的Python進行開發,且性能不輸CUDA太多,最重要的是:其代碼開源也意味著開發者享受著自由的環境,因此該開發架構也受到了很多開發者的歡迎。盡管目前Triton還只支持英偉達的GPGPU芯片,但其負責人員表示未來會支持更多廠商的芯片,做到真正的自由開發。
國內的GPGPU生態起步較晚,但近年來不斷的投入,也在2022年有了一定的成績。首先是在RISC-V(一種開源架構)中國峰會上,清華大學集成電路學院何虎副教授團隊發布了基于RISC-V的開源GPGPU實現方案,名為“承影”(Ventus),同時還給出了映射方案、指令集和微架構的實現。
而上海交大在GPGPU架構領域,同樣取得了不小的突破。2022年8月,上海交大團隊正式對外發布了自研開源GPGPU平臺“青花瓷”。“地緣政治所帶來的不確定性在這幾年有增無減,國產化的勢在必行。利用開源及開源生態所創造的芯片,就有可能解決卡脖子的困境。發布這款芯片的團隊主要成員梁教授表示。“通過十年的努力打造屬于中國的GPGPU生態,做人人都用得起GPGPU,這是我們的愿景”。
國內GPGPU公司:有所突破,但仍任重道遠
有了多樣的生態,國內的一些GPGPU公司也在研發的道路上不懈努力,推出了一些有競爭力的產品。
2022年9月,壁仞科技首次展出了BR100系列GPGPU芯片,算力創下全球紀錄。壁仞科技首款通用GPU芯片BR100,基于壁仞科技原創芯片架構研發,采用的是7nm先進制程工藝,可容納770億顆晶體管,16位浮點算力達到1000T(1T=1024G)以上、8位定點算力達到2000T以上。BR100芯片在國內率先采用Chiplet(先進封裝)技術,使得中國的通用GPU芯片邁入“每秒千萬億次計算”新時代,最為振奮人心的是,這是第一次全球通用GPU算力紀錄由中國企業制造。

隨后,浪潮AI服務器成功搭載壁仞科技自研的高端通用GPU,在多項比拼中獲評全球最佳性能,實現了國產芯片在國際AI賽場上的精彩亮相,取得了歷史性的突破。
在A股上市公司當中,目前還沒有以GPGPU為絕對主業的公司,但仍有與GPU業務有一定關系的上市公司,其中景嘉微經過多年的研發積累,公司在傳統GPU設計及特定領域應用方面形成一定的技術、品牌等綜合優勢。公司在半年報中指出,其已在通用GPU(即GPGPU)領域有所延申,正持續研發并提供相關產品。
而以CPU為主要產品的海光信息,也已研發出了基于GPGPU的DPU(Data Processing Unit,中央處理器分散單元)產品,該產品其實是GPGPU的一種。其兼容“類 CUDA”環境,解決了產品推廣過程中的軟件生態兼容性問題。公司通過參與開源軟件項目,并實現與 GPGPU 主流開發平臺的兼容。
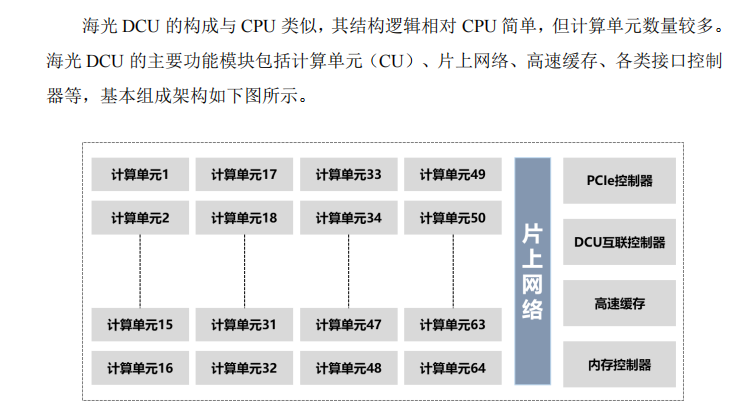
圖片來源:海光信息招股說明書
值得注意的是,盡管這兩家公司只是與GPGPU業務有一定關系,但兩家公司近日雙雙大漲,其中2月9日景嘉微20cm漲停,海光信息也大漲超13%。市場或許也已意識到算力爆發背景下,GPGPU產業的投資機會。
除了上述公司外,登臨科技、芯動力、沐曦半導體等公司,也正在GPGPU這條賽道上不斷努力著。如果這些仍未上市的GPGPU公司選擇上市,投資者也可以關注他們的動態,選擇參與打新或二級市場的投資。
綜合來看,盡管國內近兩年在GPGPU領域已取得了很多的突破,但也要看到國外一些大型廠商已在該領域經歷了數十年的發展,積累了豐富的經驗和技術,并擁有著大量的上下游市場資源。而我國的GPGPU產品不僅在生態和開發領域面臨著國外大廠卡脖子的挑戰,即使是在各自的芯片研發領域也面臨著研發周期長、投入量大、產品成功概率偏低等一系列問題。我國以CPU和GPU為代表的高端芯片設計行業的整體研發實力、創新能力和應用推廣能力仍有待提升。面對事關未來時代變革的重要產品,或許需要政府、高校和研發企業共同努力,互相共享經驗和成果,才能真正在這一領域縮小與國外的差距,實現真正的國產替代、自主可控。


